L’applicazione del deep-learning all’ambito radiologico (e in special modo a quello della Tomografia Computerizzata) è già da tempo una caratteristica rodata con risultati più che esaltanti ed entusiasmanti.
Le applicazioni sono infinite, basti pensare ai sistemi di ausilio diagnostico con CAD, alle segmentazioni automatiche e all’intero settore della radiomica; tuttavia, un ambito particolarmente interessante è quello dell’image restoration, ovvero del miglioramento dei dataset compromessi dagli artefatti la cui degradazione può severamente compromettere la qualità diagnostica.
Ho perciò voluto provare ad avvicinarmi al mondo del machine learning (e del deep learning) per conoscerlo più a fondo tentando un bellissimo esperimento “home-made”, ovvero creare un modello che si occupasse della riduzione del rumore negli esami TC e voglio raccontarvi un po’ com’è andata.
Introduzione: Il low-dose. Perchè un modello di denoising ?
E’ una storia antica. Nella pratica radiologica quotidiana, ci troviamo spesso di fronte al dilemma dose-qualità. La qualità delle immagini è collegata in modo diretto alla dose radiogena erogata. Siamo quotidianamente e costantemente alla ricerca di un compromesso per ottenere delle immagini diagnostiche e al contempo la dose radiogena più bassa possibile, secondo il cosiddetto principio ALARA (As low as reasonably achievable).
Ne ho già parlato in un precedente articolo qui e seppur l’articolo sia ormai già piuttosto vecchio (come sto invecchiando anche io, sic!) sappiamo già che esistono diverse soluzioni al tema del rumore, ovvero la degradazione che avviene nella ricostruzione finale a causa di un numero ridotto di fotoni che raggiungono il detettore; a parte l’ottimizzazione e la modulazione dei parametri di acquisizione e ricostruzione una delle più grandi possibilità che la tecnologia ci ha offerto sono gli algoritmi di ricostruzione iterativa che nella loro massima declinazione moderna model based, hanno permesso di raggiungere dei traguardi diagnostici spaventosi con miglioramenti drammatici.
L’introduzione di algoritmi di “I generazione” come MLEM (Maximum Likelihood Expectation Maximization) e OSEM (Ordered Subset Expectation Maximization) ha portato miglioramenti significativi modellando il processo di acquisizione come fenomeno statistico e considerando la natura poissoniana del rumore nei raggi X, con risultati più che soddisfacenti e costi computazionali “piuttosto” contenuti
Nella “II generazione” rappresentate dalle MBIR (Model-Based Iterative Reconstruction) vengono incorporati i modelli fisici dettagliati dell’intero sistema TC (statistiche del rumore, geometrica del fascio, caratteristiche fisiche del detettore e densità propria del paziente).
Alle tecniche di ricostruzione iterative si sono poi aggiunte anche quelle basate sul Deep-learning con enormi vantaggi iconografici e risparmi dosimetrici ma con maggior dispendio computazionale.
Su quale dominio focalizzarci ? Quello dei dati grezzi o dei dati ricostruiti ?
Le MBIR e le DL-based commerciali lavorano quasi sempre nel dominio di ricostruzione dei dati grezzi attraverso algoritmi proprietari. Perchè non provare a costruire un modello che lavori sul dominio dei dati già ricostruiti sfruttando le capacità di addestramento di una rete neurale ?
La letteratura è popolata da centinaia di modelli nati con questo scopo basati su architetture diverse e VisionCT2T-En è un esperimento che si basa su questa premessa. Sono stati creati due modelli con due architetture diverse che lavorano in sinergia:
- Denoising. per la riduzione del rumore poissoniano attraverso una Vision Transformer Token 2 Token
- Enhancement con una U-Net specializzata per aumentare la risoluzione spaziale.
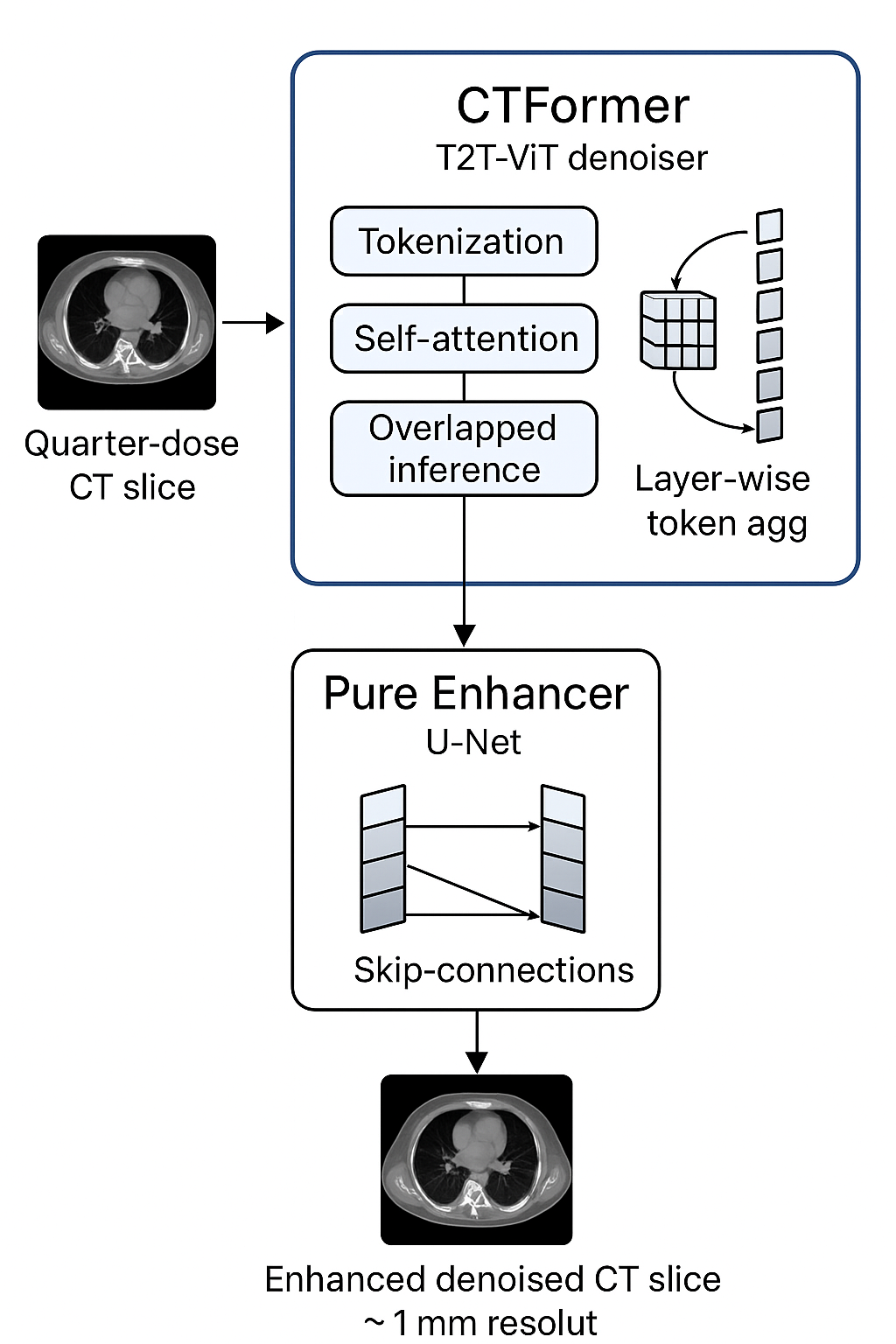
Il modello di denoising è stato addestrato sull’architettura del magnifico progetto CTFormer (https://github.com/wdayang/CTformer) mentre l’architettura di enhancement (ribattezzata qui Pure Enhancer) è una Convolutional Neural Network U-Net based ex novo ottimizzata per l’ehnancement di immagini TC .
Input: Quarter-dose CT slice
↓
CTformer (Vision Transformer):
– Ricostruzione globale strutture anatomiche
– Denoising basato su self-attention
– Output: Denoised Slice
↓
Pure Enhancer (CNN/U-Net):
– Enhancement locale dettagli
– Miglioramento contrasto/risoluzione
↓
Output: (Denoised) Enhanced 1mm-equivalent slice
Il dataset utilizzato per l’addestramento è un estratto del celebre Mayo Low Dose CT Grand Challenge che comprende vari dataset TC con accoppiamenti a dose normale e a dose ridotta del 75%. Su Kaggle è disponibile una selezione di 10 TC torace-addome a 3mm e 1mm, sia con kernel sharp che smooth.
La linea di principio è insegnare al modello le differenze tra una TC Low-Dose e una Normal Dose in modo da addestrarlo a riconoscere ed eliminare la distribuzione del rumore poissoniana (preservando le strutture anatomiche) e di migliorare la risoluzione spaziale finale attraverso l’addestramento su accoppiamenti 3mm – 1mm, in modo da avere due modelli che possano lavorare in sinergia ma all’occorrenza essere utilizzati anche singolarmente.
Gli addestramenti sono stati effettuati su Colab e Kaggle utilizzando 8 pazienti per il training, uno per la validation e uno per il testing finale.
Il codice è stato scritto in Python (libreria Pytorch) e in vibe coding con Claude.ai .
Ora, prima di mostrare i risultati, un po’ di pippone su come funzionano le due architetture potrebbe servire e quindi vi racconto un po’ più in dettaglio com’è stato realizzato questo esperimento.
Ho deciso di partire da CTformer, un magnifico modello di Vision Transformer Token 2 Token sviluppato da Wang et al. (ripropongo qui la repo https://github.com/wdayang/CTformer) per il denoising di immagini CT. L’approccio di CTFormer è particolarmente interessante perchè non sfrutta reti di convoluzioni ma un approccio di divisione delle immagini in Token con self-attention.
Facciamo l’analogia con una fotografia: invece di guardare un pixel alla volta, guardiamo in modo più coerente al contesto, saltando da un punto all’altro, creando connessioni. I Vision Transformer funzionano in modo simile: dividono l’immagine in piccole tessere (token) e permettono a ogni tessera di “comunicare” con tutte le altre attraverso i cosiddetti meccanismi di attenzione, che a mio modesto parere sono davvero affascinanti.
Nei modelli Transformer ogni elemento di attenzione viene trasformato in tre vettori:
Query (Q): cosa cercare
Key (K): cosa c’è disponibile
Value (V): l’informazione associata
Il modello confronta le Query con le Key (calcolando una somiglianza) per capire quanta attenzione dare a ciascun elemento. Questo “peso” viene poi usato per combinare i Value, ottenendo un output ponderato. Ad esempio, facendo un esempio “scolastico”, se ci trovassimo a lezione e fossimo dubbiosi su qualcosa e avessimo tanti diversi compagni in grado di darci una determinata risposta, potremmo rappresentare i tre vettori in questo modo:
- Query (Q): è la domanda (“Chi mi può spiegare bene questo argomento?”).
- Key (K): ogni compagno di classe ha una materia in cui è esperto.
- Value (V): ogni compagno ha una spiegazione pronta da dare sulla sua materia.
Confrontiamo la domanda con la risposta di ognuno. Se uno è molto preparato sull’argomento che ci interessa, gli diamo più peso (più attenzione). Se non ne sa molto, gli dai meno peso.
I pesi indicano quanto ci fidiamo della risposta di ogni compagno.
Useremo i pesi per fare una media delle risposte (Value): più uno ha peso alto, più la sua risposta conta.
Confronti la tua domanda (Query) con le competenze degli altri (Key) → ottieni un valore di somiglianza.
Applichi softmax (una sorta di normalizzazione percentuale dei diversi valori), che trasforma quei valori in pesi (numeri tra 0 e 1, che sommano a 1).
Differentemente dalle ViT (Vision Transformer) Classiche, quelle Token to Token tendono a preservare meglio le strutture spaziali perchè operano a un livello più “raffinato” sui token, su tre diversi livelli.
| Fase | Cosa succede | Output |
|---|---|---|
| Input | Immagine 512×512 | |
| Patch division | 64 patch da 64×64 | 64 token |
| T2T step 1 | 3×3 patch group, local attention | ~49 token |
| T2T step 2 | nuovo unfold, re-fold, local attention | ~36 token |
| Transformer encoder | self-attention globale tra i token | 36 token (ricchi) |
| Output head | classifica o segmenta | Classe, o mappa segmentata |
L’approccio è molto adatto a immagini TC, dove sia il contesto locale (bordi ad esempio) sia globale (asimmetrie) sono importanti.
Il problema della self-attention è la complessità quadratica e una TC standard ha una risoluzione 512×512 (vale a dire 2620000 token da gestire per ogni slice… Un inferno!).
Quindi, strategia intelligente. Croppiamo l’immagine originale in una finestra di compromesso 64×64 e da queste “patch” alleniamo il modello.
Nell’inferenza, per ricostruire l’immagine originale da 512×512, lavoreremo di nuovo su patch 64×64 che uniremo insieme con un overlap sui bordi in modo da non artefattare il risultato finale con brutte linee. Tutto fantastico da piano!
Armato dei migliori propositi, vado di git per clonare la repo e iniziare tutto eccitato l’addestramento. I primi test restituiscono dei risultati molto interessanti ma l’entusiamo inizia a spegnersi non appena provo ad esaminare in dettaglio un dicom post-processato. Tutte le informazioni relative al di fuori del range HU del pre-processing venivano clippate.
Amara scoperta: il preprocessing originale utilizzava un range HU ristretto (-160, 240) clippando tutto il resto, escludendo secondo me informazioni che sarebbero state vitali successivamente. Quindi ho cambiato il pre-processing con uno più personalizzato:
Range esteso: da -1000 HU a +2000 HU
Normalizzazione adattiva con addestramento su finestra mediastinica
Training multi-risoluzione: simultaneo su slice da 1mm, 3mm e a kernel diversi (abbiamo un dataset di oltre 10000 immagini, perchè non sfruttarlo tutto ?)
Qui arriva la parte personalizzata del Pure Enhancer (di Pure non ha molto, considerate le ingiurie volate nei diversi tentativi, ma l’aggettivo è arrivato durante una serendipity nel vibe coding).
CTformer faceva un buon denoising sul mio dataset ma sui test visivi mi sembrava troppo smooth, specialmente se applicato su immagini native a 3mm. Quindi, perchè non provare a fare un enhancement addestrando una rete che imparasse a migliorare le immagini da 3mm a 1 mm ?
Con Claude ho progettato una CNN con architettura U-Net specializzata per l’imaging CT.
#Channels
Encoder: 1 → 64 → 128 → 256 → 512 caratteristiche
Bottleneck: 1024 caratteristiche (il "cervello" del sistema)
Decoder: 512 → 256 → 128 → 64 → 1 immagine migliorataLe skip connection collegano encoder e decoder, assicurando che i dettagli fini non vadano persi durante la ricostruzione.
Volendo fare un’ analogia è come prendere una mappa, rimpicciolirla più volte (encoding) applicando diverse convoluzioni in modo da capire il contesto globale e reingrandirla (decoding) successivamente tenendo in memoria i dettagli precedenti (skip connections).
Se avrò insegnato alla rete la segmentazione delle strade, al termine del percorso a U, questa avrà imparato a colorarle e isolarle dal contesto.
La Strategia di Splitting
Come specificato più sopra la divisione dei pazienti è avvenuta in questo modo:
- 8 pazienti per training:
- 1 paziente per validation (L067)
- 1 paziente per test (L506)
Regola aurea da utilizzare per tutti i prossimi training: Nessun paziente doveva apparire in più di un set, specialmente tra set di training e validation.
Questo per evitare il “data leakage”, un errore che può invalidare completamente i risultati.
(in effetti, è una cosa accaduta per errore nei primi tentativi di training. Il PSNR di partenza era altissimo già nelle prime epoche ed era molto molto sospetto)
Il Preprocessing: Dalle HU a [0,1]
La Sfida delle Hounsfield Units
I file DICOM sono affascinanti: contengono non solo l’immagine, ma un mondo di metadati e I file DICOM hanno un management più complesso per via dei diversi livelli di livello e finestre impostabili per la visualizzazione dei diversi valori HU. Quindi, al fine di rendere compatibile l’architettura,
Il mio pipeline di preprocessing:
- Estrazione pixel dal formato DICOM
- Conversione HU usando slope e intercept specifici
- Normalizzazione nel range [0,1] che l’AI può comprendere
- Matching perfetto tra coppie quarter-dose e full-dose
Il Sistema di Patch: Pensare in Piccolo
In linea teorica una Vision Transformer può elaborare qualsiasi tipo di immagine ma è computazionalmente più dispendiosa di una CNN per via della self-attention.
La strategia delle patch si è però rivelata vincente:
- Ogni patch è un esempio di training indipendente
- L’AI impara pattern locali generalizzabili
- Posso sfruttare al massimo la memoria GPU disponibile
L’Allenamento: 200 epoche per me…posson bastare ?
La Filosofia Conservative
Ho scelto un approccio conservativo per tutto l’allenamento:
Learning Rate: 1e-5 # Lento ma sicuro
Batch Size: 16 # Quello che la GPU di colab o Kaggle permetteva
Epoche: 200 # Molto al di sotto delle 4000 usate da CTFormer ma più che
valido per un test
Il Piano in Tre Atti
Atto I (Epoche 1-100): Il modello impara le basi: distinguere rumore da tessuto, riconoscere strutture anatomiche. È la fase più eccitante perché vedi l’AI “capire” per la prima volta cosa sta guardando.
Atto II (Epoche 100-150): Riduco il learning rate e il modello inizia a raffinare i dettagli. Le loss curves diventano più stabili, i risultati più consistenti.
Atto III (Epoche 150-200): Un’ulteriore riduzione del learning rate porta il modello alla convergenza finale. È qui che emergono le differenze più sottili tra le diverse configurazioni.
Il roller-coaster emotivo
Che cosa bellissima vedere il validation loss che scende.
Che ansia vedere che improvvisamente risale per poi ritornare giù.
Che frustrazione quando, dopo 50 epoche, sembrava tutto fermo.
Sono questi i momenti che rendono la ricerca così coinvolgente: non sai mai cosa ti aspetta alla prossima epoca.
I Risultati (finalmente le immagini!)
La Verità dei Numeri Finali
Dopo 200 epoche di training, i risultati sono stati più sfaccettati di quanto immaginassi.
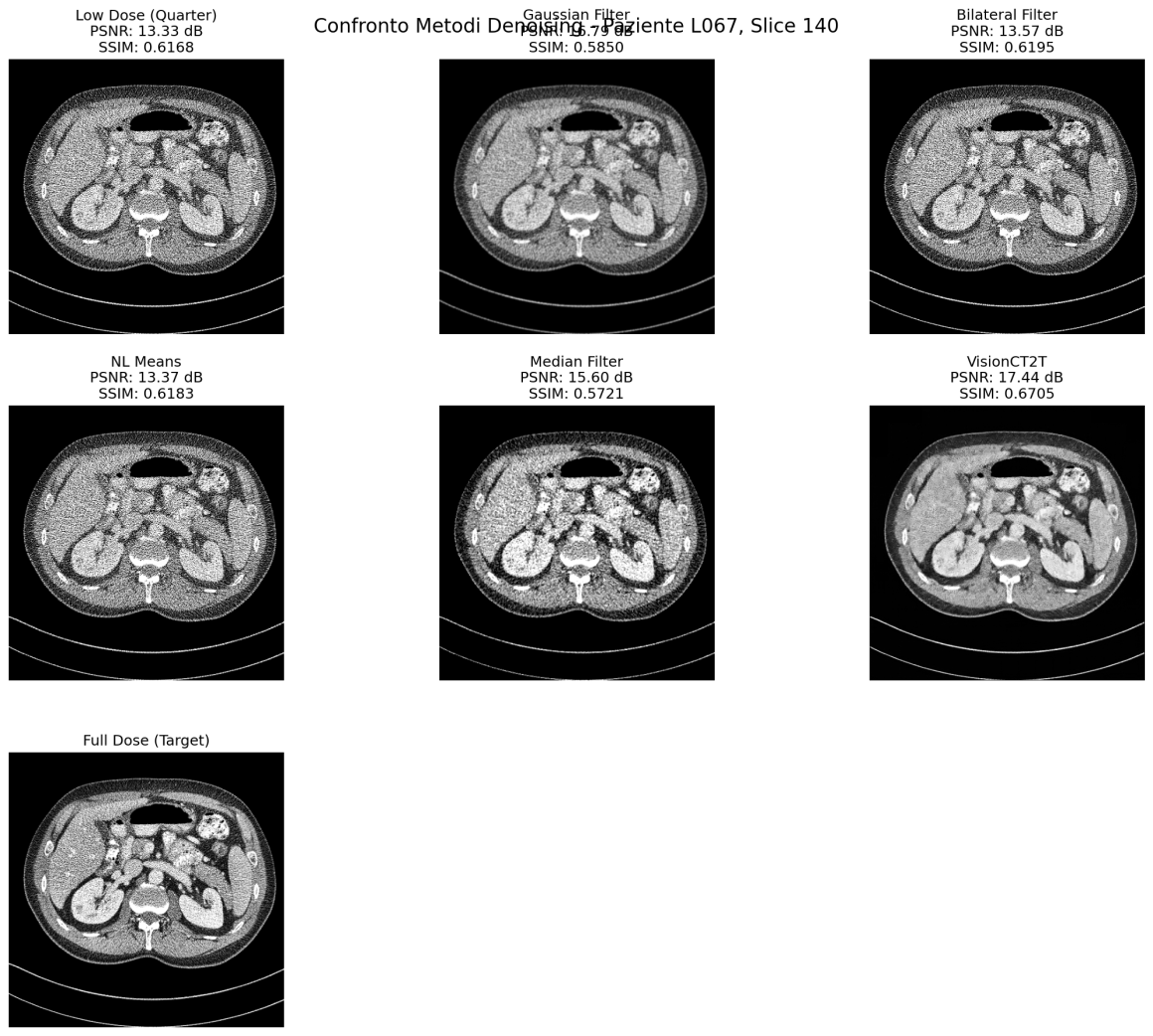
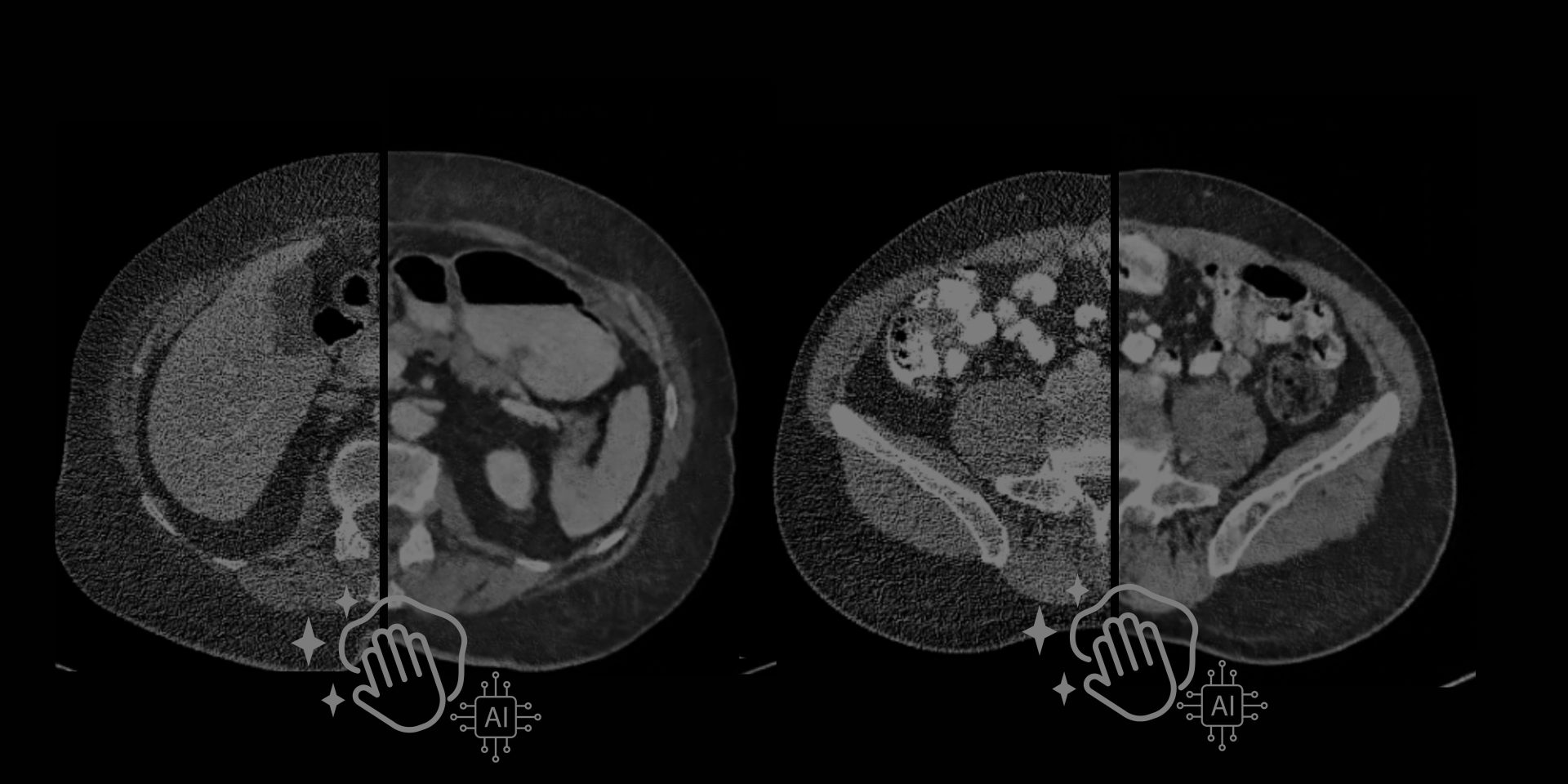
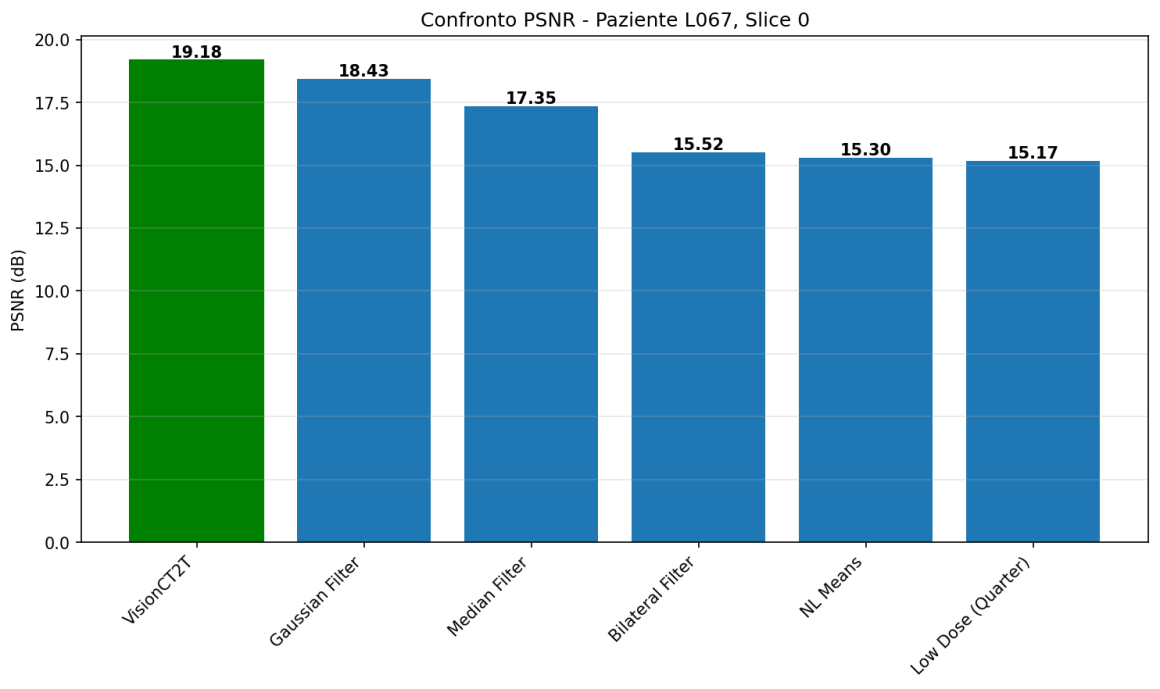
In questa immagine è possibile vedere qualche estratto grezzo con i primi esperimenti del modello. In particolar modo, qui il modello è stato addestrato solo su slice da 1mm sharp kernel senza l’intervento ibrido di Pure enhancer. La prima immagine in alto a sinistra rappresenta la slice low-dose di input e l’ultima immagine la cosiddetta ground-truth (l’immagine che il modello prende come riferimento per la sua predizione). L’immagine generata dal modello è quella con la didascalia VisionCT2T ed è stata comparata a diverse tecniche di denoising non DL. Oltre all’evidente vantaggio in termini visivi, sono altresì evidenti i miglioramenti in termini di PSNR e SSIM (due indici che identificano grosso modo il rapporto segnale-rumore e la similarità con l’immagine di partenza)
Sharp Kernel D45
- 1mm slices: 3.52 ± 0.10 dB di miglioramento
- 3mm slices: 2.95 ± 0.15 dB di miglioramento
Ed effettivamente un po’ ce lo aspettavamo. Il sistema performa meglio dove c’è più rumore.
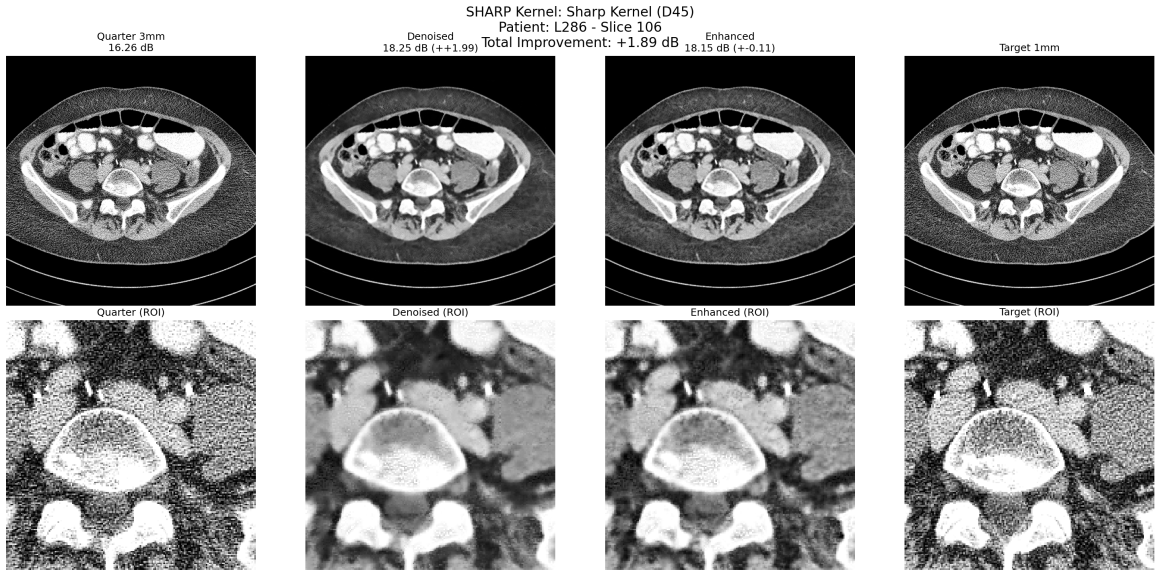
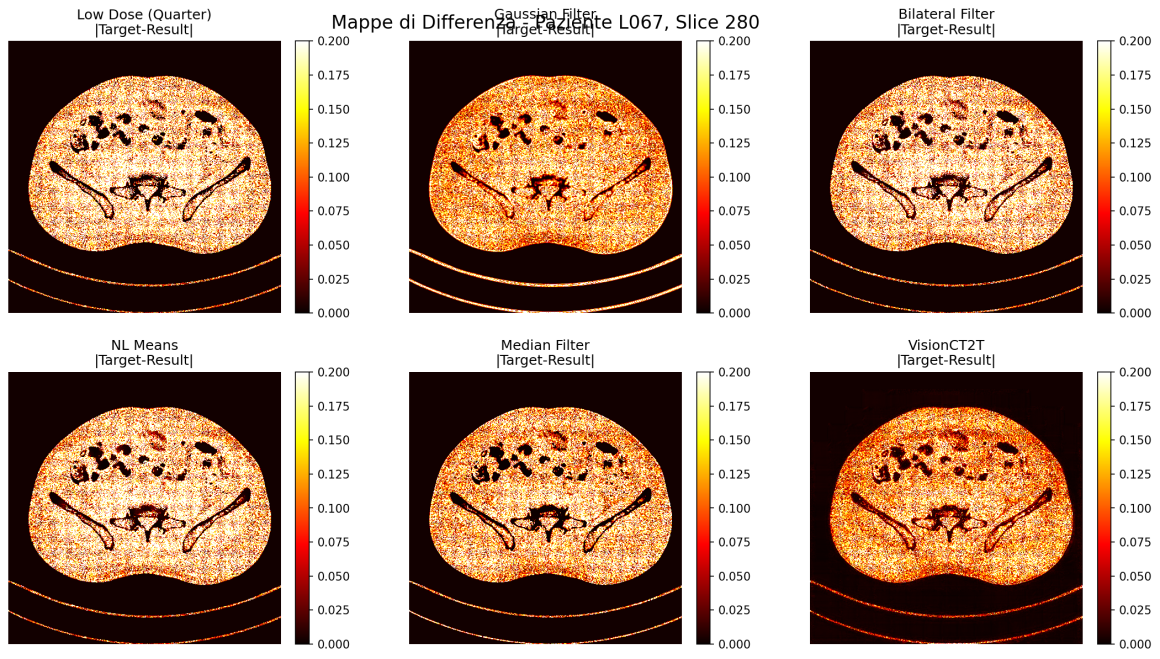
In questo confronto sono visibili i due modelli di denoising ed enhancement in azione sinergica (Enhanced). Il PSRN ha un boost di +2db. L’immagine di partenza non è così rumorosa come ci si aspetta perchè è un taglio da 3mm, il target da 1mm (l’idea era di allenare il modello nel miglioramento della risoluzione spaziale).
Soft Kernel B30
- 1mm slices: 2.04 ± 0.11 dB di miglioramento
- 3mm slices: 0.82 ± 0.19 dB di miglioramento
Anche qui niente di nuovo. I kernel smooth sono meno rumorosi e il miglioramento è solo marginale.
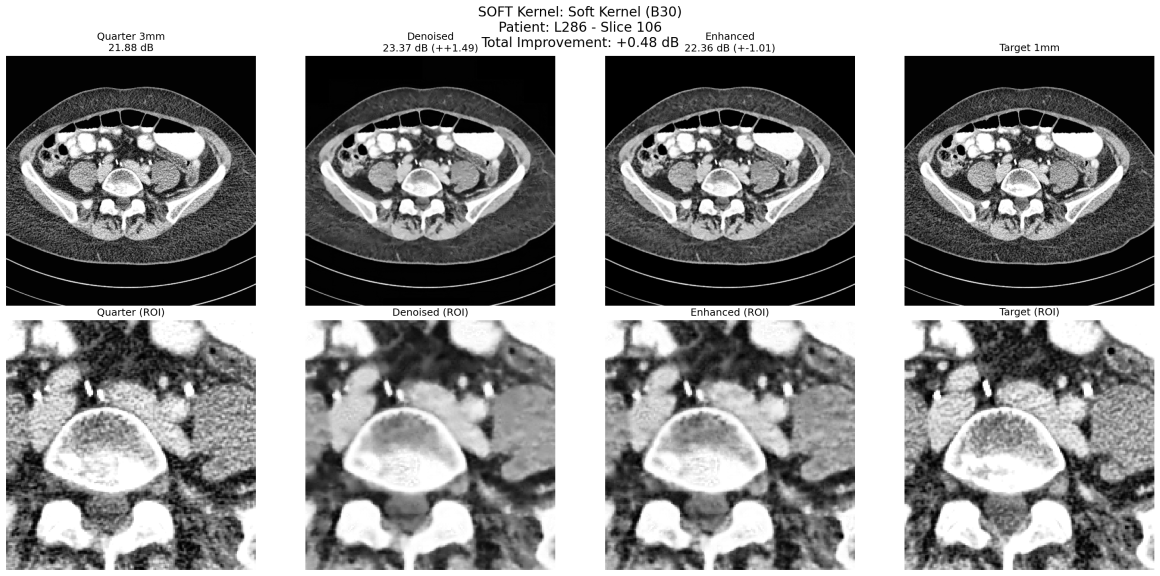
In questo confronto sono visibili i due modelli che lavorano su un kernel Smooth. Il PSRN ha un boost di circa +1.5db.
E’ interessante però notare l’apparente “aumento di risoluzione” (input 3mm – ground truth 1mm)
L’analisi degli effect size conferma quello che già conoscevamo
- Thickness Effect (Cohen’s d = 0.83): Lo spessore delle slice è importante
- Kernel Effect (Cohen’s d = 1.68): Il tipo di kernel è ancora più determinante
Dati statistici generale
- 75% delle configurazioni hanno un miglioramento significativo (>1.5 dB)
- 67% delle configurazioni sono altamente significative (>2.0 dB)

Le Sfide Tecniche
La Battaglia della Memoria GPU
16GB di VRAM sembrano tanti finché non provi a processare immagini mediche ad alta risoluzione. Oltre alle imprecazioni, ho imparato l’arte del batch size optimization, del gradient accumulation, e del memory management. La parsimonia sui MB a disposizione è particolarmente importante.
L’Overfitting: Il Nemico Silenzioso
Con solo 10 pazienti, il rischio di overfitting era altissimo. Quindi è stato implementato:
- Dropout strategico (10% nel bottleneck)
- Data augmentation aggressiva (8 varianti per ogni patch)
- Cross-validation per ogni paziente
La Sincronizzazione delle Patch
La parte più delicata: assicurarmi che ogni patch quarter-dose fosse perfettamente allineata con la sua gemella full-dose. L’algoritmo quindi:
- Estrae patch dalle stesse coordinate
- Applica identiche trasformazioni a entrambe
- Verifica l’allineamento prima del training
Conclusioni e progetti futuri
L’esperienza di lavorare con il deep-learning è stata molto molto stimolante (a tratti quasi ossessiva) e senza dubbio apre infinite porte. Siamo abituati a immaginare il deep learning medicale “casalingo” per compiti di segmentazione e detection, ma gli sviluppi possono essere molto variegati.
Fortunatamente, anche senza un’enorme conoscenza di Python grazie al vibe coding, è assolutamente possibile strutturare architetture in un tempo brevissimo. Mi sento di consigliare Claude AI per questo scopo che mi è sembrato l’AI engine meglio ottimizzato.
I prossimi progetti prevedono prima di tutto di allargare le capacità del modello su diversi distretti anatomici (specialmente testa-collo) e di effettuare un training con window shifting, in modo da migliorare anche le finestre Lung e Brain, oltre a sperimentare con altre metodologie (diffusione magari ?) e di integrare questo modello con uno di super-resolution x4 da applicarsi negli studi specialistici, come le cardio-TC, per contrastare il blooming.
L’articolo sarà aggiornato con repository e un plugin slicer per testare il modello in un container diverso, nel frattempo vi auguro una buona Estate e a presto!!


Update: Inferenza su dataset mai visto nel training – Confronto con metodiche commerciali
Sarebbe interessante però fare un confronto diretto con una ricostruzione iterativa ed una basata sul deep learning, peccato che… Aspettate un attimo, Kaggle ha un dataset di CT Low dose-full dose con ricostruzioni in retroproiezioni filtrate, con metodica iterativa (AIDR3D – Canon) e AiCE (Canon). Cavolo! Allora diventa interessante, quindi possiamo stressare un po’ il modello e vedere come compara rispetto a soluzioni commerciali! Che bello!
Prima di tutto strutturiamo un nuovo notebook (su Kaggle stavolta) per ricaricare entrambi i checkpoint e studiare la struttura del nuovo dataset; poi creiamo gli accoppiamenti e facciamo i primi confronti per vedere che cosa aspettarci.

Da sinistra: immagine low dose (40 mAs, ricostruita con retroproiezione filtrata semplice), Full dose (300 mAs), ricostruzione iterativa AIDR3D, AiCE, mappa delle differenze Full dose/Low dose, istogramma comparativa dei delta rumore.
Ristrutturiamo l’architettura per poter fare l’inferenza usando lo stesso pre-processing del training.
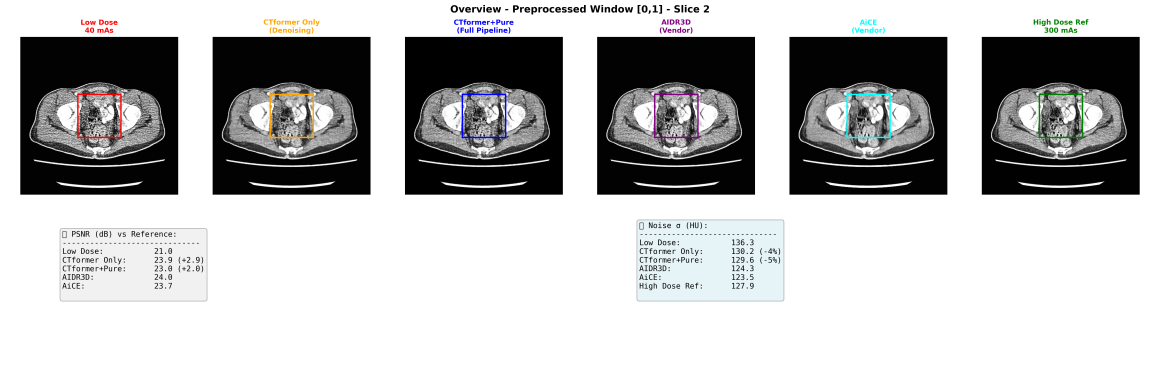
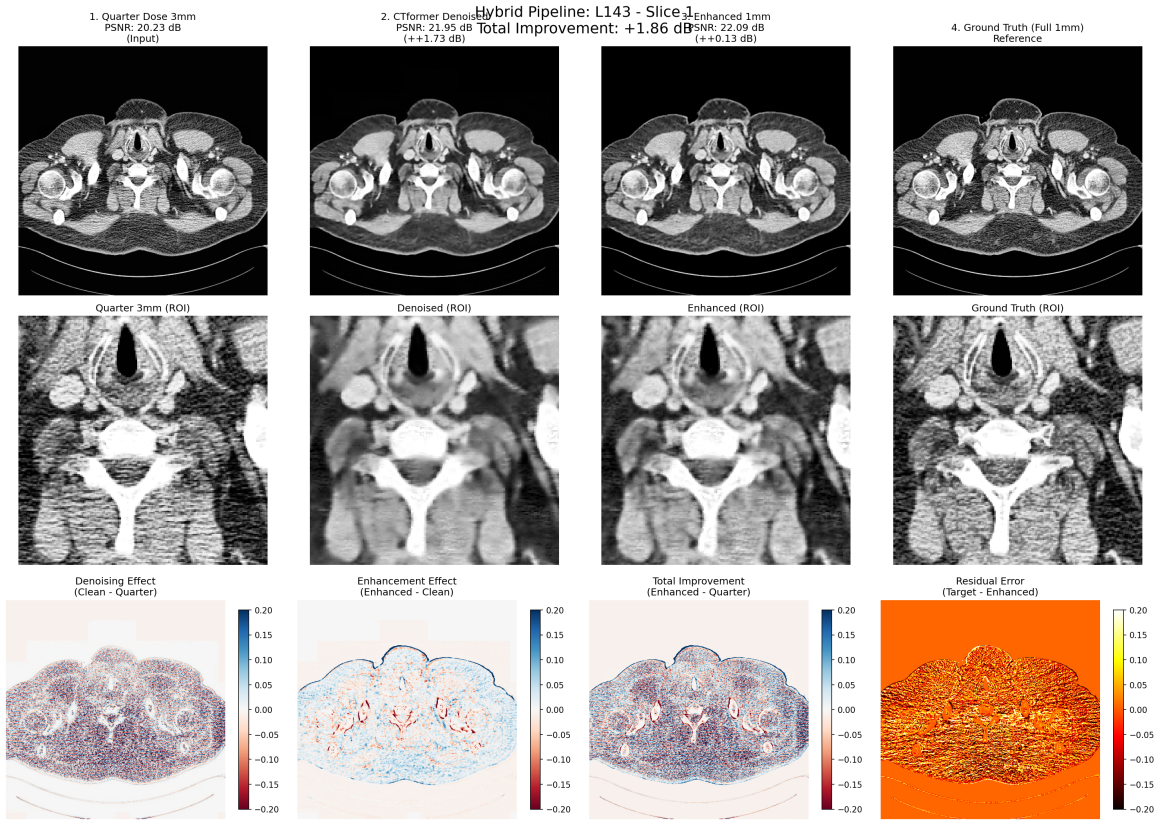
I dati quantitativi sono molto incoraggianti. Aumento del PSRN di quasi 3dB (Il modello con il “Pure Enhancer” aumenta un po’ il rumore perchè cerca di incrementare la risoluzione spaziale, è fondamentalmente uno sharpening). Riduzione media del rumore di circa il 5%, niente male. Il denoising anche a livello qualitativo è efficace rispetto alla full dose e quasi comparabile alla ground truth.
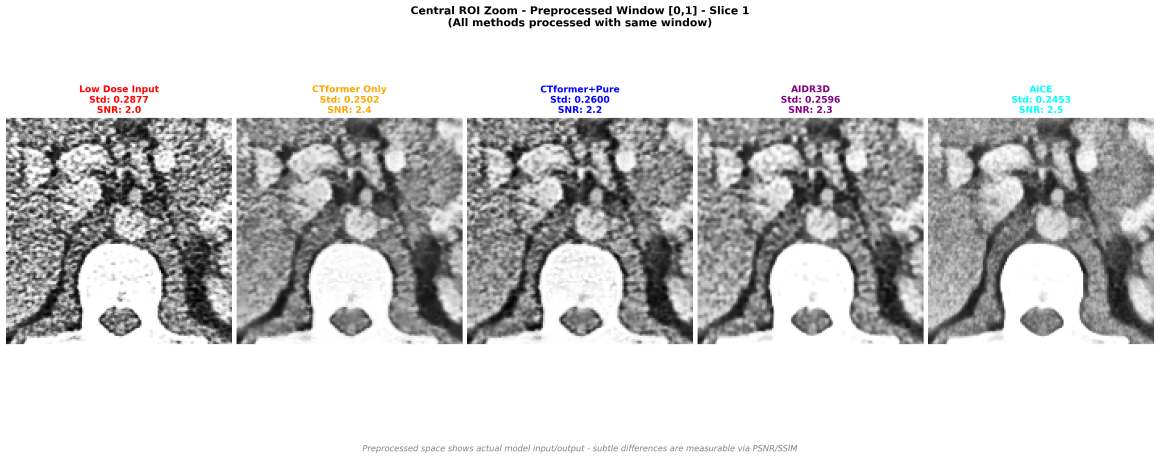
Visualizzazione con finestra di preprocessing usata nel training (il modello lavora solo in questo dominio, in una versione production ready andrebbe testato anche su finestre diverse).
I risultati qualitativi per me sono abbastanza soddisfacenti. CTFormer da solo raggiunge un livello di denoising validissimo e l’intera Pipeline CTFormer+Pure Enhancer, al netto di perdita di 0.2 dB di PSNR, raggiunge un risultato qualitativo simile a AIDR3D, rimanendo però molto al di sotto di AICE (e questo ovviamente non ci meraviglia affatto).

Alla finestra normalizzata le differenze sono meno evidenti ma le metriche quantitative danno un miglioramento di AIDR3D rispetto al nostro modello, seppur lo sharpening di VisionCT2-En sia maggiore (che può essere preferibile in questa finestra).
Permane la supremazia schiacciante di AICE.
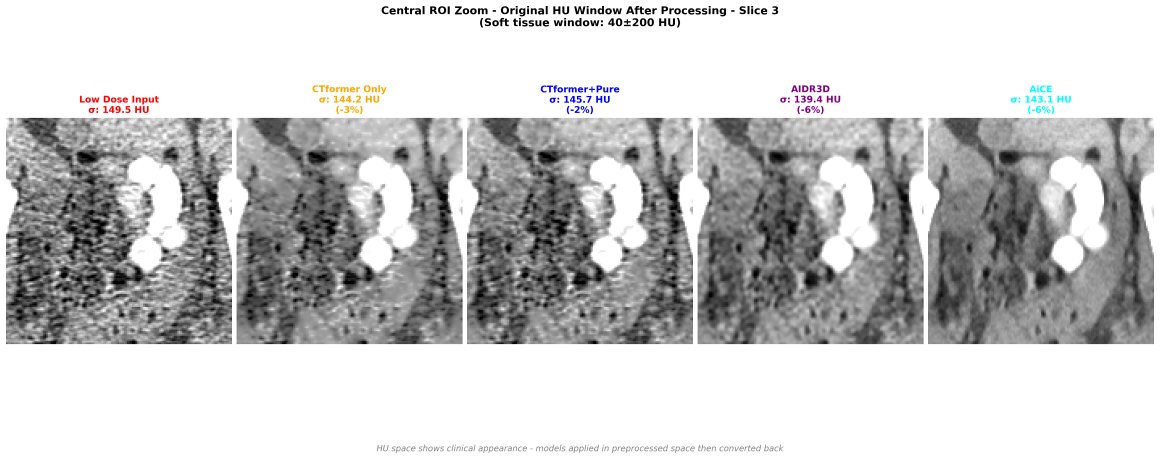
Qua viene il difficile: uno zoom in un’area complicata, molto rumorosa, con tante interfacce (contrasto, muscolo, grasso, aria) con un rumore di partenza particolarmente alto. Non c’è il full dose di riferimento e quindi prenderemo AICE per quello (che è anche meglio). Il denoising di CTFormer è stato minimo, Pure Enhancer ha aumentato un po’ la risoluzione spaziale permettendo di vedere meglio l’area iso/iperdensa che nel low dose era praticamente distrutta. AIDR3D qui fa un lavoro egregio bilanciando il risultato tra edge enhancement e smoothness. Ah! Non ve l’ho detto, questo NON è un paziente reale, è un phantom!! E’ costruito benissimo!
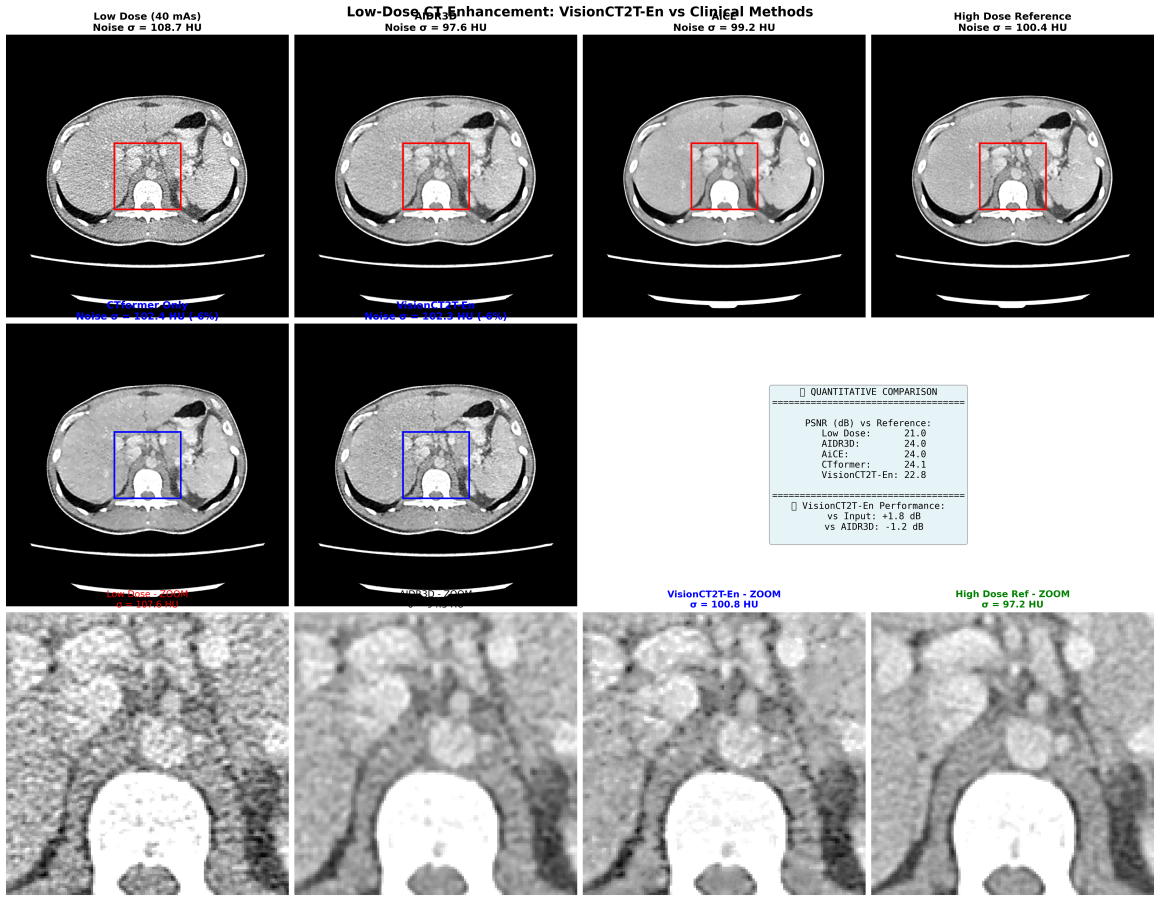
Qui un confronto interessante. Alla stessa finestra, AIDR3D nonostante abbia un confronto quantitativo più vantaggioso, sembra apparire molto più piatto e quindi, decido arbitrariamente di assegnare questo punto a VisionCT2T-En.
Forse perchè mi sembra oggettivamente così o forse perchè ho un bias dovuto al bene che voglio a questo modello e lo sappiamo: “Ogni scarrafon è bello a mamma soia!”
Ovviamente non è mai stato nelle mie intenzioni testare e allenare un modello definitivo che riuscisse a risolvere per sempre il problema del rumore quantico (seh, lallero!) però è interessante notare come il “progresso tecnologico” sia effettivamente tangibile e applicabile in modo così “semplice” e immediato, senza necessità di alcun hardware particolare grazie al cloud computing;
Ci sono due conclusioni molto importanti che ho in qualche modo tratto da questa esperienza. La prima è che non servono hardware ultraperfomanti per trainare un modello di base. Il cloud computing ha un’esperienza molto userfriendly e costi tutto sommato accettabili in relazione alla qualità (vedi colab che, al netto delle limitazioni orarie, offre comunque GPU molto valide con notebook molto fluidi, a un costo di circa 11 euro al mese per un account pro).
La seconda conclusione è più un’evidenza dell’estrema velocità di evoluzione del deep Learning. Quello che è ormai è vecchio e causa conflitti di dipendenze ha soltanto un paio di anni. E’ una crescita esponenziale spaventosa e rimane molto difficile stare al passo.
Infatti, proprio pochi giorni fa Google ha rilasciato il suo modello più avanzato di LLM per l’ambito medico: MedGemma, una sorta di Gemini tailored per l’ambito sanitario, multimodale e allenato su tantissimi dataset di immagini radiologiche, oftalmiche e dermatologiche e soprattutto, è open Source!! Beh, farò qualche altro esperimento a breve! A presto!!